Benutzer-Werkzeuge
se:parallelrechner
**Dies ist eine alte Version des Dokuments!**
Inhaltsverzeichnis
Parallelrechner
Klausur
- Codeabschnitte verifizieren
- Online-Learning anschauen
- Programm als Lückentext
- Verstehen der wichtigsten Funktionen (send/recv)
- Architekturen verstehen (Shared Memory etc.)
* Metriken verstehen, Metriken (Formeln) für neue Topologie entwickeln - Leistungsbewertung (Gesetze Amdahl etc.)
- keine virtuellen Topologien
- OpenMP eher allgemein (Kombination mit MPI)
- Matrizenrechnung fliegt raus
- Bibliotheken für Parallelrechner nur oberflächlich
* Leseempfehlung- Gesetze Amdahl etc.
- MPI-Standard
Lehrbrief ist erlaubt!
Online-Kurs
Einstieg in parallele Programmierung
- Voraussetzungen für effektive Parallelisierung
- schnelle Verbindung zwischen Prozessoren und Speicher und den einzelnen Prozessen, sowie schnelle Datenübertragung in und aus dem Speicher
- Protokoll für Interprozesskommunikation
- die Algorithmen müssen parallelisierbar sein und in kleine Teilprobleme aufgeteilt werden können
- Mechanismus zur Verteilung der Aufgaben an die Prozesse
- Computerarchitekturen nach Flynn 1972
- Single Instruction Single Data (SISD)
- Multiple Instruction Single Data (MISD)
- Single Instruction Multiple Data (SIMD)
- 1 CPU zur Steuerung und mehrere CPUs mit eigenem Speicher
- Steuer-CPU sendet Broadcasts und die anderen CPU rechnen, abhängig von konditionalen Bedingungen im Code
- Nachteil: viele CPUs bleiben idle
- Multiple Instruction Multiple Data (MIMD)
- jede CPU hat übernimmt sowohl Steuerung als auch Berechnung
- Programme werden von jeder CPU unabhängig von den anderen ausgeführt → asynchron
- 3 Typen: shared memory (CPUs teilen sich gemeinsamen Speicher), distributed memory (Knoten, die zusammen ein Problem lösen) und SMP (Kombination der beiden vorherigen)
- Shared-Memory MIMD
- Verbindung zwischen CPUs und Speicher via Bus oder Switch
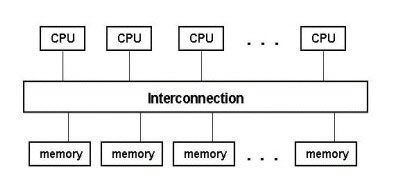
- CPUs haben zusätzlich internen Speicher: Register und Cache
- Problem bei Verwendung von Cache: Variablen haben nach Änderung durch anderen Prozess vielleicht falschen Wert → Protokoll wird benötigt zum Ermitteln solcher Fälle
- Distributed-Memory MIMD
- jede CPU hat eigenen Speicher → Menge von Knoten ergeben den gesamten Parallelrechner

- da kein Zugriff auf den Speicher der anderen Knoten besteht, müssen geeignete Programmiertechniken verwendet werden, um den Prozessen den Zugriff zu ermöglichen
- SMP Cluster
- Symmetric Multi-Processing
- Netzwerk (→ distributed) aus shared memory Clustern
- Beispiel: Earth Simulator
- Modelle paralleler Programmierung
- message passing model
- Prozesse kommunizieren über Nachrichten
- der Programmierer steuert die Aufteilung der Daten und der Berechnung auf die Prozesse und deren Kommunikation
- wird hauptsächlich bei verteilten Systemen angewendet
- MPI ist der Standard für message passing → kann auch auf shared memory clustern laufen, schöpft dort aber nicht die Zugriffe auf das shared memory aus
- directives-based data-parallel model
- serieller Code wird durch Quelltextkommentare parallelisiert, die den Compiler anweisen, wie er die Daten und Berechnung zu verteilen hat
- Details der Verteilung werden dem Compiler überlassen
- üblicherweise auf shared memory Systemen verwendet
- OpenMP ist ein Standard, ein weiterer ist High Performance Fortran (HPF)
- die Direktiven werden hauptsächlich verwendet um Schleifen zu parallelisieren (small-scale parallelization), während MPI auf Programmebene parallelisiert (large-scale)
- Kombination von MPI und OpenMP
- kann Vorteile beider Systeme vereinen: shared memory access und message passing zwischen Nodes
- Design paralleler Programme
- parallele Programme bestehen aus mehreren Instanzen serieller Programme, die über Bibliotheksfunktionen kommunizieren, die sich wie folgt einteilen lassen:
- initialize, manage, terminate → Start der Kommunikation, Anzahl der Prozesse ermitteln, Subgroups erstellen
- point-to-point: send/receive zwischen Prozesspaaren
- Kommunikation zwischen Prozessgruppen → Synchronisation, verteilte Berechnung
- Erstellen von Datentypen
- Dekomposition des Problems
- domain decomposition / data parallelism
- Problem lässt sich durch serielle Abarbeitung von mehreren Aufgaben auf mehreren Datenbereichen lösen
- Daten werden aufgeteilt und an die verschiedenen Prozesse verteilt und berechnet, hin und wieder müssen die Prozesse Daten austauschen
- Vorteil: nur ein Steuerungsfluss → Single Program Multiple Data (SPMD)
- anwendbar, wenn sich Daten leicht auf verschiedene Bereiche aufteilen lassen (z.B. Lösen von Differentialgleichungen)
- functional decomposition / task parallelism
- besser als domain decomposition, wenn die Berechnung der einzelnen Teilbereiche der Daten unterschiedlich lange dauert → alle warten auf den langsamsten Prozess
- Problem lässt sich als Abarbeitung von mehreren Aufgaben gleichzeitig lösen
- implementiert als Client-Server-Modell
- Load Balancing
- Arbeit wird gleichmäßig auf die Prozesse verteilt, damit keine idle sind
- einfach, wenn die gleichen Aufgaben auf mehreren Datenbereichen durchzuführen sind
- Ausführungszeit
- 3 Komponenten wirken sich auf die Ausführungszeit aus
- Berechnungszeit: die Zeit, die nur für die Berechnung des Problems verwendet wird
- Wartezeit: Zeit, die ein Prozess auf einen anderen wartet (Beispiel: zentralisierte Kommunikation)
- Kommunikationszeit: Zeit, die zum Senden und Empfangen von Nachrichten gebraucht wird (Latenz ist die Zeit um die Kommunikation vorzubereiten, Bandbreite ist die Übertragungsgeschwindigkeit), muss minimiert werden, da sie Overhead im Vergleich zu serieller Bearbeitung darstellt
- Prozesswartezeit verringern
- latency hiding: Prozess bekommt andere Aufgaben, während er auf die Antwort eines anderen Prozesses wartet
- asynchrone Kommunikation


Einstieg in MPI
- Standard-Implementierung für message passing, keine Bibliothek sonder nur API-Spezifikation
- MPI-Programme bestehen aus mindestens zwei autonomen Prozessen, die ihren eigenen Code ausführen
- die Prozesse kommunizieren über MPI-Funktionen und werden über ihren Rang identifiziert
- die Anzahl der Prozesse ist nicht zur Laufzeit änderbar, sondern wird beim Aufruf des Programms festgelegt
- MPI-1 wurde 1994 entwickelt vom MPI-Forum, dessen Mitglieder aus 60 Organisationen stammen
- der Standard definiert Namen, Aufrufsequenzen und Rückgabewerte von Funktionen → Interface
- die Implementierung ist dem jeweiligen Hersteller überlassen → Optimierung für Plattformen möglich
- MPI ist für viele Plattformen verfügbar
- MPI-2 wurde bereits definiert, ist aber noch nicht auf allen Plattform verfügbar (Features: paralleles I/O, C++-Bindings etc.)
- Ziele von MPI
- Portabilität des Quelltextes
- effiziente Implementierungen für viele Architekturen
- von MPI wird nicht definiert/angeboten
- wie die Programme zu starten sind
- dynamische Änderung der Prozesszahl zur Laufzeit
- MPI kann verwendet werden, wenn
- portabler Code benötigt wird
- Anwendungen beschleunigt werden müssen und Schleifen-Parallelisierung nicht ausreicht
- MPI sollte nicht verwendet werden, wenn
- Schleifen-Parallelisierung ausreicht
- es bereits parallele Bibliothken für den Fachbereich gibt (z.B. mathematische Bibliotheken)
- man überhaupt keine Parallelisierung benötigt
- Typen von MPI-Routinen
- point-to-point communication: 1-zu-1-Kommunikation
- collective communication: 1-zu-viele-Kommunikation, Synchronisierung
- process groups
- Process topologies
- Environment management and inquiry
- point-to-point communication
- elementare Kommunikation zwischen 2 Prozessen: send/receive, beide Prozesse müssen aktiv handeln
- Kommunikation per Nachrichten mit Envelope (source, destination, tag etc.) und Body (Daten)
- Teile des Nachrichten-Bodys: buffer (Speicherplatz der Daten), datatype (primitive oder eigene Datentypen), count (Anzahl der Datentypen)
- MPI definiert eigene Datentypen um unabhängig von der Implementierung z.B. der Gleitkommazahlen auf den unterschiedlichen Plattformen zu bleiben
- Modi des Nachrichtenversands
- standard
- synchron: Senden ist erst nach Bestätigung des Empfängers abgeschlossen
- buffered: Senden ist abgeschlossen, nachdem die Daten in den lokalen Puffer kopiert wurden
- ready
- erfolgreiches Senden bedeutet, dass der ursprüngliche Speicherplatz der Daten überschrieben werden kann
- Receive ist beendet, wenn die Daten tatsächlich angekommen sind
- blockierende Kommunikation: die send-/receive-Routine kehrt erst zurück, wenn die Daten tatsächlich versendet wurden
- nicht-blockierende Kommunikation: die send-/receive-Routine kehrt sofort nach dem Aufruf zurück ohne sicherzustellen, dass die Daten tatsächlich versendet wurden, der Prozess kann andere Aufgaben übernehmen und später prüfen, ob die Daten angekommen sind
- collective communications
- ein communicator ist eine Gruppe von Prozessen, die miteinander kommunizieren dürfen, alle Prozesse gehören stets zu MPICOMMWORLD
- collective operations übertragen Daten zwischen allen Prozessen einer Gruppe
- Synchronisation: alle Prozesse warten, bis sie einen bestimmten Punkt erreicht haben
- Datenbewegung: Daten werden an alle Prozesse verteilt
- kollektive Berechnung: ein Prozess einer Gruppe sammelt Daten von anderen Prozessen ein und führt Operationen auf den Daten durch
- Vorteile der collective operations im Gegensatz zu point-to-point
- weniger Fehlermöglichkeiten → eine Codezeile pro Aufruf
- lesbarerer Quelltext
- meist schneller
- Broadcast: ein Prozess sendet Daten an alle Prozesse seiner Gruppe
- Scatter und Gather: Verteilen und Einsammeln von Daten zwischen Prozessen
- Reduktion: ein Root-Prozess sammelt Daten von mehreren Prozessen ein und berechnet einen Einzelwert
- Prozessgruppe: geordnete Gruppe von Prozessen, die jeweils einen Rang (=ID) haben, Prozesse können Mitglied mehrerer Gruppen sein
- Prozesstopologien: Anordnung von Prozessen in geometrischen Figuren (Grid oder Graph), rein virtuelle Anordnung unabhängig von physikalischer Anordnung der Prozessoren, ermöglichen effiziente Kommunikation und erleichtern die Programmierung
- Management und Abfragen der Umgebung: initialisieren und beenden von Prozessen, Rangermittlung
se/parallelrechner.1230916098.txt.gz · Zuletzt geändert: 2014-04-05 11:42 (Externe Bearbeitung)
Seiten-Werkzeuge
Falls nicht anders bezeichnet, ist der Inhalt dieses Wikis unter der folgenden Lizenz veröffentlicht: CC Attribution-Noncommercial-Share Alike 4.0 International
