Benutzer-Werkzeuge
se:parallelrechner
Inhaltsverzeichnis
Parallelrechner
Klausur
- Codeabschnitte verifizieren
- Online-Learning anschauen
- Programm als Lückentext
- Verstehen der wichtigsten Funktionen (send/recv)
- Architekturen verstehen (Shared Memory etc.)
* Metriken verstehen, Metriken (Formeln) für neue Topologie entwickeln - Leistungsbewertung (Gesetze Amdahl etc.)
- OpenMP eher allgemein (Kombination mit MPI)
- Bibliotheken für Parallelrechner nur oberflächlich
* Leseempfehlung- Gesetze Amdahl etc.
- MPI-Standard
- NICHT
- virtuellen Topologien
- Matrizenrechnung
- Lehrbrief ist erlaubt!
Einstieg in Parallelrechner
- Arten von Parallelrechnern
- Symmetrische Multiprozessorsysteme (SMP): übliche Rechner mit mehreren Prozessoren (auch die heutigen MultiCore-PCs)
- Rechner-Cluster: übliche Rechnerknoten verbunden über ein überdurchschnittlich schnelles Netzwerk, keine direkte Eingabemöglichkeit sondern Zugang über Eingangsknoten
- Vernetzte Workstations (NOW): übliche Workstations, die einen ad-hoc Paralllelrechner mit begrenzter Leistung bilden
- Grids: Internet-basierter Zusammenschluss verteilter Rechner (z.B. SETI)
- die meisten Parallelrechner laufen unter Linux und verwenden Standard-APIs für die Programmierung (MPI, OpenMP, ScaLAPACK)
Architekturen und Klassifizierungen von Parallelrechnern
- Speichergekoppelt / shared memory

- alle Prozessoren müssen den gemeinsamen Speicher über das Verbindungsnetz ansprechen → Flaschenhals
- 1 Adressraum, n Prozessoren (durch VN begrenzt), alle Speicherzugriffe über das VN (braucht also hohe Bandbreite)
- Programmierung: Parallelsprachen oder parallele Spracherweiterungen, OpenMP, normale Threads
* Nachrichtengekoppelt / message passing 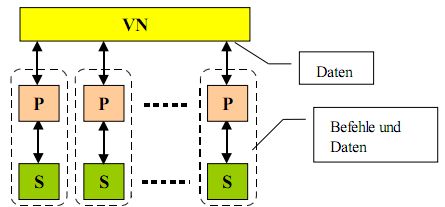
- viele Prozessoren möglich, VN mit geringer Bandbreite, skalierbar, anwendbar für Cluster/NOW
* n Adressräume, n Prozessoren, Nachrichtenaustausch über VN * Programmierung: Standardsprachen mit Bibliotheken für Nachrichtenaustausch (MPI)
* Hybridlösungen
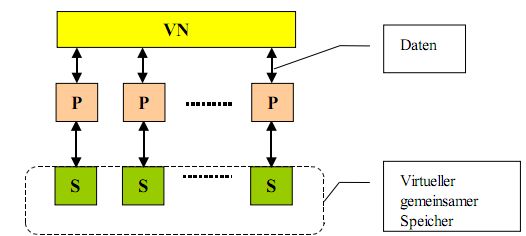
- Beispiel: verteilter gemeinsamer Speicher, Speicherzugriff außerhalb des eigenen Moduls erfolgt über VN
- Klassifikation nach Flynn
- SISD: ein Befehlsstrom, ein Datenstrom (normaler PC), ein Befehl verarbeitet einen Datensatz (herkömmliche Rechnerarchitektur eines seriellen Rechners)
- SIMD: ein Befehlsstrom, mehrere Datenströme (Cray, Vektorrechner), ein Befehl verarbeitet mehrere Datensätze, z.B. n Prozessoren führen zu einem Zeitpunkt den gleichen Befehl aber mit unterschiedlichen Daten aus
- MISD: mehrere Befehlsströme, ein Datenstrom (praktisch keine), mehrere Befehle verarbeiten den gleichen Datensatz (diese Rechnerarchitektur ist nie realisiert worden)
- MIMD: mehrere Befehlsströme, mehrere Datenströme (Merhprozessorsysteme und verteilte Systeme), unterschiedliche Befehle verarbeiten unterschiedliche Datensätze (dies ist das Konzept fast aller modernen Parallelrechner)
- SPMD und MPMD
- MPMD: Multiple Program, multiple Data (jeder Prozessor führt sein eigenes Programm aus, Master verteilt Arbeit an Worker)
- SPMD: Single Program, multiple Data (ein einziges Programm enthält Abschnitte für Master und Worker)
- Vor-/Nachteile
- SPMD: größere Portabilität, einfacher zu verwalten, viele MPMD-Programme können als SPMD-Programme formuliert werden.
- MPMD: größere Flexibilität, schwieriger zu verwalten
* Zugriffsweise auf den Speicher
- Uniform Memory Access: gleichförmiger Speicherzugriff (Tanzsaal-Architektur)
- Non-Uniform Memory Access: ungleichförmiger Speicherzugriff (z.B. lokaler Cachespeicher und globaler Speicher, Cray)
- Cache-Only Memory Access: nur Cache-Zugriffe
- No Remote Memory Access: nur lokale Speicherzugriffe (Grid, NOW)
* Parallelisierungsstrategien - Gebietszerlegung (engl. domain decomposition)
- Funktionale Aufteilung (engl. functional decomposition)
- Verteilung von Einzelaufträgen (engl. task farming)



Statische Verbindungsnetze
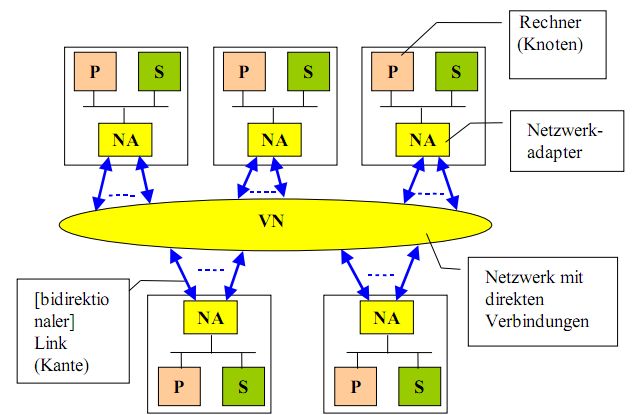
- Verbindungsstrukturen bestehen aus festen Links zwischen Rechnern
- regelmäßige Strukturen werden bevorzugt
- einfacheres Routing
- Symmetrie → leichter verständlich, leichtere Entwicklung, Prozessoren lassen sich leichter tauschen
- Modularität → leichter erweiterbar und umformbar
- Metriken
- Distanz zwischen zwei Knoten: das Minimum aller Pfadlängen zwischen dem betrachteten Knotenpaar
- Durchmesser: die größtmögliche Distanz in einem Graphen
- Halbierungsbreite: Mindestanzahl der Kanten, die entfernt werden müssen, damit ein Graph in zwei gleichgroße Hälften zerfällt
- typische Netzwerke
- Ring
- Baum
- Fat Tree
- Gitter ohne/mit Wraparound
- Hyperkubus (N = 2k)
- wenn k um 1 inkrementiert wird, verdoppelt sich die Knotenzahl und die alten Knoten erhalten ein zusätzliches Bit 0 (die neuen 1) und werden mit den entsprechenden neuen Knoten verbunden
- vollständige Vernetzung
- Stern
- Skalierbarkeit und Emulation
- Was ist das kleinste Netzinkrement, das hinzugefügt werden muss, um das nächstgrößere Netz der gleichen Topologie zu erhalten?
- Wie ist die Abhängigkeit der Effizienz einer Topologie von der Knotenzahl?
- Emulation: Abbildung eines Gastgraphen G auf einen Wirtsgrafen H, bei der alle Knoten von G auf Knoten von H zum Liegen kommen. Jede Kante von G wird auf eine oder mehrere Kanten von H abgebildet.
* Beispiele: Ring im 2D-Torus, Baum im Gitter, Gitter im Hyperkubus * Verlangsamung durch Emulation * Knotenlast: die größte Zahl der Gastknoten, die auf einem Wirtsknoten zu liegen kommen * Dilatation: die Länge des längsten Pfades in H, auf den eine beliebige Kante von G abgebildet wird * Andrang/Kantenlast: die größte Zahl der Kanten von G, die auf dieselbe Kante in H abgebildet werden * Beispiele für Dilatation 1: Gitter -> Hyperkubus, Ring -> Gitter

Dynamische Verbindungsnetzwerke
- Verbindungsarten
- Leitungsvermittlung: eine physikalische Verbindung wird für die Dauer der gesamten Übertragung zugewiesen
- Paketvermittlung: ein Paket wird an das VN abgegeben und von diesem über Zwischenknoten an den Zielknoten übertragen
- Routing-Strategien
- Store-and-Forward: jeder Zwischenknoten speichert die Nachricht vollständig, bevor sie dem nächsten Knoten übergeben wird (Übertragungszeit ist proportional zur Knotenzahl)
- Cut-Through: Nachrichten werden in Teile gespalten und sofort weitergeschickt (Knoten müssen gleichzeitig senden und empfangen können)
- Wormhole: Nachricht wird in kleine Teile (Flits, 1-2 Byte) zerteilt und zunächst wird nur der Kopf der Nachricht verschickt, wenn dieser den Knoten verlässt, wird der Rest der Nachricht angefordert
- Vergleich
- Latenz wächst bei SaF mit Knotenzahl, dafür wird Netz nicht belastet, da Knoten sofort wieder zur Verfügung stehen
- beim Wormhole werden die Knoten lange blockiert und es kann zu Deadlocks kommen, allerdings bleibt die Latenz mit steigender Knotenzahl konstant
* typische dynamische Verbindungsnetze
- Merkmale
- Bandbreite (Bits/s)
- Latenzzeit (Verzögerung erster Bit zwischen Sender und Empfänger)
- Fehlertoleranz
- Skalierbarkeit
- einstufig: Bus, Crossbar, Shuffle
- mehrstufig: Banyan, Benes, CLOS
* Bus: höchstens 1 Eingang wird zu allen Ausgängen durchgeschaltet -> sehr verbreitet aber auf kleine Teilnehmerzahl beschränkt * Crossbar: ermöglicht gleichzeitige Kommunikation zwischen verschiedenen Teilnehmerpaaren * Shuffle: vereinfachter Crossbar mit eingeschränkten Steuereingängen * Shuffle mit Broadcast-Erweiterung: zusätzliches Broadcast-Bit zur Erweiterung der Schaltfunktion (1 Eingang -> 2 Ausgänge) * Banyan: Shuffle in Grundschaltung in mehreren Ebenen, Blockierungen sind möglich * CLOS: besteht aus Crossbars
Grundbegriffe der Leistungsbewertung
- Tcomp Rechenzeit, Tcomm Kommunikationszeit, Tser Ausführungszeit der seriellen Programmversion, Tpar Ausführungszeit der parallelen Programmversion, n Anzahl Knoten
- Granularität: Länge der seriellen Codeabschnitte zwischen Kommunikations- und Synchronisationsbefehlen
- computation / communication ratio: Tcomp / Tcomm
- Beschleunigung: S(n) = Tser / Tpar
- Effizienz: S(n) / n
- Kosten: n * Tpar
* Gesetz von Amdahl: S(n) = (s + p) / (s + p/n)- geht von einem konstanten seriellen Anteil im Programm aus → Grenze für Speedup, nicht-skalierbare Anwendungen
- Die Verbesserung der Leistung des Gesamtsystems durch Verbesserung einer Komponente ist limitiert durch den Umfang der Verwendung der Komponente.
- Gesetz von Gustavson-Barsis: Ss(n) = n + (1 - n) s
* geht von einer konstanten Laufzeit des seriellen Anteils im Programm aus -> skalierbare Anwendungen, können bei wachsendem Problem mit mehr Prozessoren ausgestattet werden * Verbesserung der Genauigkeit/Problemgröße eines parallelen Verfahrens durch Steigerung der Prozessorzahl bei gleich bleibender Ausführungszeit
Nachrichtenaustausch
- Nachrichten werden zwischen den Prozessen verschickt, indem der Absender diese in einen Umschlag mit Empfänger und Sender verpackt und ggfs. mit einem Tag versieht
- Prozesserzeugung
- statisch: alle Prozesse werden vor der Ausführung spezifiziert
- dynamisch: neue Prozesse können während der Ausführung anderer Prozesse erzeugt werden (z.B. Master-Worker-Struktur)
- ein Prozess versendet eine Nachricht, indem er
- den/die Empfänger nennt
- den Wert (Adresse und Datentyp) bereitstellt
- optional die Nachricht mit einem Tag versieht
- ein Prozess empfängt eine Nachricht, indem er
- den Absender nennt (exakt oder beliebiger Absender)
- den Typ der Daten und die Zieladresse nennt
- optional einen Tag angibt (z.B. "dringend")
- synchroner/blockierender Nachrichtenaustausch
- erst Send oder erst Receive möglich
- Prozesse warten, bis die Nachricht übertragen wurde (und blockieren solange)
- asynchroner/nicht blockierender Nachrichtenaustausch
* Empfänger kann ein IRecv absetzen und später mit Wait schauen, ob die Nachricht angekommen ist
Online-Kurs
Einstieg in parallele Programmierung
- Voraussetzungen für effektive Parallelisierung
- schnelle Verbindung zwischen Prozessoren und Speicher und den einzelnen Prozessen, sowie schnelle Datenübertragung in und aus dem Speicher
- Protokoll für Interprozesskommunikation
- die Algorithmen müssen parallelisierbar sein und in kleine Teilprobleme aufgeteilt werden können
- Mechanismus zur Verteilung der Aufgaben an die Prozesse
- Computerarchitekturen nach Flynn 1972
- Single Instruction Single Data (SISD)
- Multiple Instruction Single Data (MISD)
- Single Instruction Multiple Data (SIMD)
- 1 CPU zur Steuerung und mehrere CPUs mit eigenem Speicher
- Steuer-CPU sendet Broadcasts und die anderen CPU rechnen, abhängig von konditionalen Bedingungen im Code
- Nachteil: viele CPUs bleiben idle
- Multiple Instruction Multiple Data (MIMD)
- jede CPU hat übernimmt sowohl Steuerung als auch Berechnung
- Programme werden von jeder CPU unabhängig von den anderen ausgeführt → asynchron
- 3 Typen: shared memory (CPUs teilen sich gemeinsamen Speicher), distributed memory (Knoten, die zusammen ein Problem lösen) und SMP (Kombination der beiden vorherigen)
- Shared-Memory MIMD
- Verbindung zwischen CPUs und Speicher via Bus oder Switch
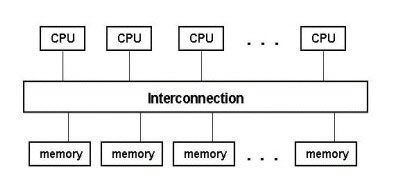
- CPUs haben zusätzlich internen Speicher: Register und Cache
- Problem bei Verwendung von Cache: Variablen haben nach Änderung durch anderen Prozess vielleicht falschen Wert → Protokoll wird benötigt zum Ermitteln solcher Fälle
- Distributed-Memory MIMD
- jede CPU hat eigenen Speicher → Menge von Knoten ergeben den gesamten Parallelrechner

- da kein Zugriff auf den Speicher der anderen Knoten besteht, müssen geeignete Programmiertechniken verwendet werden, um den Prozessen den Zugriff zu ermöglichen
- SMP Cluster
- Symmetric Multi-Processing
- Netzwerk (→ distributed) aus shared memory Clustern
- Beispiel: Earth Simulator
- Modelle paralleler Programmierung
- message passing model
- Prozesse kommunizieren über Nachrichten
- der Programmierer steuert die Aufteilung der Daten und der Berechnung auf die Prozesse und deren Kommunikation
- wird hauptsächlich bei verteilten Systemen angewendet
- MPI ist der Standard für message passing → kann auch auf shared memory clustern laufen, schöpft dort aber nicht die Zugriffe auf das shared memory aus
- directives-based data-parallel model
- serieller Code wird durch Quelltextkommentare parallelisiert, die den Compiler anweisen, wie er die Daten und Berechnung zu verteilen hat
- Details der Verteilung werden dem Compiler überlassen
- üblicherweise auf shared memory Systemen verwendet
- OpenMP ist ein Standard, ein weiterer ist High Performance Fortran (HPF)
- die Direktiven werden hauptsächlich verwendet um Schleifen zu parallelisieren (small-scale parallelization), während MPI auf Programmebene parallelisiert (large-scale)
- Kombination von MPI und OpenMP
- kann Vorteile beider Systeme vereinen: shared memory access und message passing zwischen Nodes
- Design paralleler Programme
- parallele Programme bestehen aus mehreren Instanzen serieller Programme, die über Bibliotheksfunktionen kommunizieren, die sich wie folgt einteilen lassen:
- initialize, manage, terminate → Start der Kommunikation, Anzahl der Prozesse ermitteln, Subgroups erstellen
- point-to-point: send/receive zwischen Prozesspaaren
- Kommunikation zwischen Prozessgruppen → Synchronisation, verteilte Berechnung
- Erstellen von Datentypen
- Dekomposition des Problems
- domain decomposition / data parallelism
- Problem lässt sich durch serielle Abarbeitung von mehreren Aufgaben auf mehreren Datenbereichen lösen
- Daten werden aufgeteilt und an die verschiedenen Prozesse verteilt und berechnet, hin und wieder müssen die Prozesse Daten austauschen
- Vorteil: nur ein Steuerungsfluss → Single Program Multiple Data (SPMD)
- anwendbar, wenn sich Daten leicht auf verschiedene Bereiche aufteilen lassen (z.B. Lösen von Differentialgleichungen)
- functional decomposition / task parallelism
- besser als domain decomposition, wenn die Berechnung der einzelnen Teilbereiche der Daten unterschiedlich lange dauert → alle warten auf den langsamsten Prozess
- Problem lässt sich als Abarbeitung von mehreren Aufgaben gleichzeitig lösen
- implementiert als Client-Server-Modell
- Load Balancing
- Arbeit wird gleichmäßig auf die Prozesse verteilt, damit keine idle sind
- einfach, wenn die gleichen Aufgaben auf mehreren Datenbereichen durchzuführen sind
- Ausführungszeit
- 3 Komponenten wirken sich auf die Ausführungszeit aus
- Berechnungszeit: die Zeit, die nur für die Berechnung des Problems verwendet wird
- Wartezeit: Zeit, die ein Prozess auf einen anderen wartet (Beispiel: zentralisierte Kommunikation)
- Kommunikationszeit: Zeit, die zum Senden und Empfangen von Nachrichten gebraucht wird (Latenz ist die Zeit um die Kommunikation vorzubereiten, Bandbreite ist die Übertragungsgeschwindigkeit), muss minimiert werden, da sie Overhead im Vergleich zu serieller Bearbeitung darstellt
- Prozesswartezeit verringern
- latency hiding: Prozess bekommt andere Aufgaben, während er auf die Antwort eines anderen Prozesses wartet
- asynchrone Kommunikation


Einstieg in MPI
- Standard-Implementierung für message passing, keine Bibliothek sonder nur API-Spezifikation
- MPI-Programme bestehen aus mindestens zwei autonomen Prozessen, die ihren eigenen Code ausführen
- die Prozesse kommunizieren über MPI-Funktionen und werden über ihren Rang identifiziert
- die Anzahl der Prozesse ist nicht zur Laufzeit änderbar, sondern wird beim Aufruf des Programms festgelegt
- MPI-1 wurde 1994 entwickelt vom MPI-Forum, dessen Mitglieder aus 60 Organisationen stammen
- der Standard definiert Namen, Aufrufsequenzen und Rückgabewerte von Funktionen → Interface
- die Implementierung ist dem jeweiligen Hersteller überlassen → Optimierung für Plattformen möglich
- MPI ist für viele Plattformen verfügbar
- MPI-2 wurde bereits definiert, ist aber noch nicht auf allen Plattform verfügbar (Features: paralleles I/O, C++-Bindings etc.)
- Ziele von MPI
- Portabilität des Quelltextes
- effiziente Implementierungen für viele Architekturen
- von MPI wird nicht definiert/angeboten
- wie die Programme zu starten sind
- dynamische Änderung der Prozesszahl zur Laufzeit
- MPI kann verwendet werden, wenn
- portabler Code benötigt wird
- Anwendungen beschleunigt werden müssen und Schleifen-Parallelisierung nicht ausreicht
- MPI sollte nicht verwendet werden, wenn
- Schleifen-Parallelisierung ausreicht
- es bereits parallele Bibliothken für den Fachbereich gibt (z.B. mathematische Bibliotheken)
- man überhaupt keine Parallelisierung benötigt
- Typen von MPI-Routinen
- point-to-point communication: 1-zu-1-Kommunikation
- collective communication: 1-zu-viele-Kommunikation, Synchronisierung
- process groups
- Process topologies
- Environment management and inquiry
- point-to-point communication
- elementare Kommunikation zwischen 2 Prozessen: send/receive, beide Prozesse müssen aktiv handeln
- Kommunikation per Nachrichten mit Envelope (source, destination, tag etc.) und Body (Daten)
- Teile des Nachrichten-Bodys: buffer (Speicherplatz der Daten), datatype (primitive oder eigene Datentypen), count (Anzahl der Datentypen)
- MPI definiert eigene Datentypen um unabhängig von der Implementierung z.B. der Gleitkommazahlen auf den unterschiedlichen Plattformen zu bleiben
- Modi des Nachrichtenversands
- standard
- synchron: Senden ist erst nach Bestätigung des Empfängers abgeschlossen
- buffered: Senden ist abgeschlossen, nachdem die Daten in den lokalen Puffer kopiert wurden
- ready
- erfolgreiches Senden bedeutet, dass der ursprüngliche Speicherplatz der Daten überschrieben werden kann
- Receive ist beendet, wenn die Daten tatsächlich angekommen sind
- blockierende Kommunikation: die send-/receive-Routine kehrt erst zurück, wenn die Daten tatsächlich versendet wurden
- nicht-blockierende Kommunikation: die send-/receive-Routine kehrt sofort nach dem Aufruf zurück ohne sicherzustellen, dass die Daten tatsächlich versendet wurden, der Prozess kann andere Aufgaben übernehmen und später prüfen, ob die Daten angekommen sind
- collective communications
- ein communicator ist eine Gruppe von Prozessen, die miteinander kommunizieren dürfen, alle Prozesse gehören stets zu MPICOMMWORLD
- collective operations übertragen Daten zwischen allen Prozessen einer Gruppe
- Synchronisation: alle Prozesse warten, bis sie einen bestimmten Punkt erreicht haben
- Datenbewegung: Daten werden an alle Prozesse verteilt
- kollektive Berechnung: ein Prozess einer Gruppe sammelt Daten von anderen Prozessen ein und führt Operationen auf den Daten durch
- Vorteile der collective operations im Gegensatz zu point-to-point
- weniger Fehlermöglichkeiten → eine Codezeile pro Aufruf
- lesbarerer Quelltext
- meist schneller
- Broadcast: ein Prozess sendet Daten an alle Prozesse seiner Gruppe
- Scatter und Gather: Verteilen und Einsammeln von Daten zwischen Prozessen
- Reduktion: ein Root-Prozess sammelt Daten von mehreren Prozessen ein und berechnet einen Einzelwert
- Prozessgruppe: geordnete Gruppe von Prozessen, die jeweils einen Rang (=ID) haben, Prozesse können Mitglied mehrerer Gruppen sein
- Prozesstopologien: Anordnung von Prozessen in geometrischen Figuren (Grid oder Graph), rein virtuelle Anordnung unabhängig von physikalischer Anordnung der Prozessoren, ermöglichen effiziente Kommunikation und erleichtern die Programmierung
- Management und Abfragen der Umgebung: initialisieren und beenden von Prozessen, Rangermittlung
MPI Programmstruktur
- grundsätzlicher Aufbau von MPI-Programmen
include MPI header file variable declarations initialize the MPI environment ...do computation and MPI communication calls... close MPI communications
- MPI-Funktionsnamen beginnen immer mit
MPIsein)und habenintals Rückgabewert (sollteMPISUCCESS - Liste aller MPI-Konstanten: http://www.netlib.org/utk/papers/mpi-book/mpi-book.html
- MPI-Datentypen einer Send-/Receive-Kombination müssen übereinstimmen
- MPI-Standarddatentypen:
MPICHAR,,MPISHORTMPIINT,,MPILONGMPIUNSIGNEDCHAR,MPIUNSIGNEDSHORT,MPIUNSIGNED,,MPIUNSIGNEDLONG,MPIFLOATMPIDOUBLE,,MPILONGDOUBLE,MPIBYTEMPIPACKED,* Spezielle Datentypen:MPICOMMMPISTATUS,MPIDATATYPE - Initialisierung von MPI:
int err; err = MPI_Init(&argc, &argv);
- Prozesse kommunizieren über Communicator miteinander (z.B.
MPICOMMWORLD), ihren Rang in einem Communicator erhalten sie mitint MPI_Comm_rank(MPI_Comm comm, int *rank);
- Die Anzahl der Prozesse in einem Communicator ermittelt
int MPI_Comm_size(MPI_Comm comm, int *size);
- MPI wird beendet mit
err = MPI_Finalize();
- HelloWorld mit MPI:
#include <stdio.h> #include <mpi.h> void main (int argc, char *argv[]) { int myrank, size; MPI_Init(&argc, &argv); // Initialize MPI MPI_Comm_rank(MPI_COMM_WORLD, &myrank); // Get my rank MPI_Comm_size(MPI_COMM_WORLD, &size); // Get the total number of processors printf("Processor %d of %d: Hello World!\n", myrank, size); MPI_Finalize(); // Terminate MPI }
Point-to-point Kommunikation
- Punkt-zu-Punkt-Verbindungen stellen die fundamentale Kommunikation zwischen Prozessen dar
- Probleme: welche Nachricht wird verarbeitet, wenn mehrere empfangen werden können; synchrone/asynchrone Kommunikation
- beide Teilnehmer (Sender und Empfänger müssen aktiv partizipieren)
- Sender und Empfänger arbeiten meist asynchron (Sender sendet z.B. erst nachdem der Empfänger schon empfangen will)
- Nachrichten bestehen aus
- Envelope: Source, Destination, Communicator, Tag
- Source wird implizit ermittelt, alle anderen Werte müssen explizit angegeben werden
- Body: Buffer, Datatype, Count
- verschickte, noch nicht empfangene Nachrichten hängen in der pending queue, aus der die empfangenden Prozesse die nächsten Nachrichten auswählen können (nicht nur simple FIFO-Queue)
- Nachricht blockierend versenden:
int MPI_Send(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm);
- alle Parameter sind Input-Parameter
* Nachricht blockierend empfangen:int MPI_Recv(void *buf, int count, MPI_Datatype dtype, int source, int tag, MPI_Comm comm, MPI_Status *status);
source,tagundcommunicatormüssen den Werten ausMPISendundentsprechen (Wildcards sind erlaubt fürsourceundtag) *bufferundstatussind Output-Parameter, der Rest Input * Sender und Empfänger müssen denselben Datentyp verwenden, sonst kann es zu unvorhergesehenen Ergebnissen kommen * wenn der Puffer länger ist als angegeben, kommt es zu einem FehlerMPIANYSOURCE
* Wildcards beim Empfangen *undMPIANYTAGsind die Wildcards * überstatus.MPISOURCEstatus.MPITAGzurückkehrt heißt das nicht, dass die Nachricht angekommen ist, sondern nur, dass sie MPI übergeben wurdekönnen die konkreten Werte ermittelt werden * tatsächliche Anzahl an Elementen in der empfangenen Nachricht ermitteln (countist lediglich das Maximum der möglichen Werte): <code>int MPIGetcount(MPIStatus *status, MPIDatatype dtype, int *count);</code> * Beim Senden können zwei unterschiedliche Dinge passieren * die Nachricht wird in einen MPI-Puffer kopiert und im Hintergrund verschickt * die Nachricht bleibt in den Programmvariablen bis der empfangende Prozess bereit zum Empfangen ist * wennMPISEND
- bei der Kommunikation muss man darauf achten, Deadlocks zu verhindern
- Kommunikation genau planen (z.B. P1 send dann recv, P2 recv dann send)
- auch P1 send dann recv, P2 send dann recv kann zu einem Deadlock führen, wenn die Nachrichten zu groß für den MPI-Puffer sind
- blockierende und nicht-blockierende Kommunikation können gemischt werden (sogar bei derselben Nachricht)
- nicht-blockierende Kommunikation benötigt zwei Aufrufe: posting eines sends und eines receives
- die Aufrufe werden beendet entweder durch "Nachfragen" des Prozesses oder durch Warten des Prozesses
- die postings werdne über ein Request-Handle identifiziert, dass der aufrufende Prozess nutzen kann um den Status abzufragen
- nicht-blockierendes Senden:
int MPI_Isend(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm, MPI_Request *request);
- das I steht für Initiate
- der Aufruf startet lediglich das Senden, es muss ein zusätzlicher Aufruf erfolgen, um den Vorgang abzuschließen
- die Parameter sollten nicht gelesen oder geschrieben werden, solange die Aktion nicht abgeschlossen ist
- nicht-blockierendes Empfangen:
int MPI_Irecv(void *buf, int count, MPI_Datatype dtype, int source, int tag, MPI_Comm comm, MPI_Request *request);
- Warten auf Beendigung des nicht-blockierenden Aufrufs:
int MPI_Wait( MPI_Request *request, MPI_Status *status );
- Testen auf Beendigung des nicht-blockierenden Aufrufs:
int MPI_Test( MPI_Request *request, int *flag, MPI_Status *status );
- Vorteil von nicht-blockierendem Aufruf: weniger Gefahr durch Deadlocks, Möglichkeit zum latency hiding
- Beispiel für latency hiding mit IRECV:
MPI_IRECV(...,request) ... arrived=FALSE while (arrived == FALSE) { "work planned for processor to do while waiting for message data" MPI_TEST(request,arrived,status) } "work planned for processor to do with the message data"
- Nachteil: höhere Code-Komplexität → schwierigeres Debugging und schwierigere Wartung
- Sendemodi (Senden abgeschlossen, wenn…)
- Standard: Puffern der Nachricht durch MPI oder Synchronisieren der beiden beteiligten Prozesse
- synchron: der empfangene Prozess muss begonnen haben, die Nachricht zu empfangen
- Ready: ein passendes receive muss bereits vorliegen
- buffered: MPI muss einen Puffer verwenden, der jedoch manuell gesteuert werden kann (
MPIBUFFERATTACHundMPIBUFFERDETACH)
Kommunikation nicht-zusammenhängender Daten
- üblicherweise werden Daten übertragen, die den gleichen Datentyp haben und in einem Array zusammenhängen
- es können aber auch Daten übertragen werden, die nicht zusammenhängen
- Beispiel: Submatrix versenden in C: (Anzahl Zeilen) * Nachricht mit (Anzahl Spalten) Elementen
for (i=0; i<n; ++i) { MPI_Send(&a[k+i][l], m, MPI_DOUBLE, dest, tag, MPI_COMM_WORLD); }- Vorteil: bekannte Funktionen zum Senden können verwendet werden
- Nachteil: Overhead durch mehrere Sendeoperationen
- Daten vor dem Versenden in einen zusammenhängenden Puffer kopieren und diesen versenden
p = &buffer; for (i=k; i<k+n; ++i) { for(j=l; j<l+m; ++j) { *(p++) = a[i][j]; } } MPI_Send(p, n*m, MPI_DOUBLE, dest, tag, MPI_COMM_WORLD)- man sollte nicht in Versuchung geraten, Datentypen vor dem Übertragen eigenmächtig zu casten, da unterschiedliche MPI-Implementierungen die Werte falsch interpretieren könnten
- stattdessen sollte
MPIPACKmuss dann anstattverwendet werden, das genau diese Aufgabe übernimmt * <code>count = 0; for(i=0; i<n; i++){ MPIPack(&a[k+i][l], m, MPIDOUBLE, buffer, bufsize, count, MPICOMMWORLD); } MPISend(buffer, count, MPIPACKED, dest, tag, MPICOMMWORLD);</code> *MPIUNPACKMPIRECVverwendet wurde, man könnte sie also ganz "normal" z.B. als Double empfangenzum Empfangen verwendet werden (mitMPIPACKSIZEkann die hierfür benötigte Größe des Puffers ermittelt werden) * an den Nachrichten selbst kann man nicht erkennen, obMPIPACK - Vorteil: man kann Nachrichten sukzessive erstellen und beliebige Datentypen verwenden
- Nachteil: Overhead zum Verpacken der Daten
- abgeleitete Datentypen
- werden aus den Standarddatentypen erstellt und ermöglichen ein "on-the-fly"-Packing: der Puffer und das Hin- und Herkopieren entfallen
- TODO?
Kollektive Kommunikation
- MPI stellt einige Funktionen zur Verfügung, um häufig benötigte Kommunikationsmuster zu implementieren
- die Funktionen übertragen Nachrichten zu allen Prozessen einer Gruppe und daher muss jeder Prozess die Funktion aufrufen
int MPIBarrier ( MPIComm comm )synchronisiert Prozesse ohne Daten zu übertragen; evtl. Overhead, daher sparsam verwendenint MPIBcast ( void* buffer, int count, MPIDatatype datatype, int rank, MPIComm comm )schickt Daten vom Rootprozess an alle anderen * <code>#include <mpi.h> void main(int argc, char argv[]) { int rank; double param; MPIInit(&argc, &argv); MPICommrank(MPICOMMWORLD,&rank); if(rank==5) param=23.0; MPIBcast(¶m,1,MPIDOUBLE,5,MPICOMMWORLD); printf("P:%d after broadcast parameter is %f \n",rank,param); MPIFinalize(); }</code> *int MPIReduce ( void* sendbuffer, void* recvbuffer, int count, MPIDatatype datatype, MPIOp operation, int rank, MPIComm comm ): sammelt Daten von den Prozessen ein, reduziert diese Daten auf einen Wert, speichert den reduzierten Wert im Rootprozess *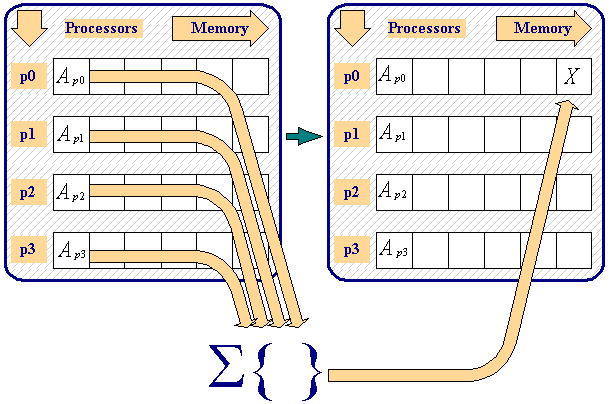 *
* count,datatype,rankmüssen in allen Prozessen gleich sein *operationwird auf den Werten durchgeführt (sum, min, max etc.) * <code>#include <stdio.h> #include <mpi.h> void main(int argc, char *argv[]) { int rank; int source,result,root; / run on 10 processors / MPIInit(&argc, &argv); MPICommrank(MPICOMMWORLD,&rank); root=7; source=rank+1; MPIBarrier(MPICOMMWORLD); MPIReduce(&source,&result,1,MPIINT,MPIPROD,root,MPICOMMWORLD); if(rank==root) printf("P:%d MPIPROD result is %d \n",rank,result); MPIFinalize(); }</code> *int MPIGather ( void* sendbuffer, int sendcount, MPIdatatype sendtype, void* recvbuffer, int recvcount, MPIDatatype recvtype, int rank, MPIComm comm )sammelt Daten von allen Prozessen im Rootprozess *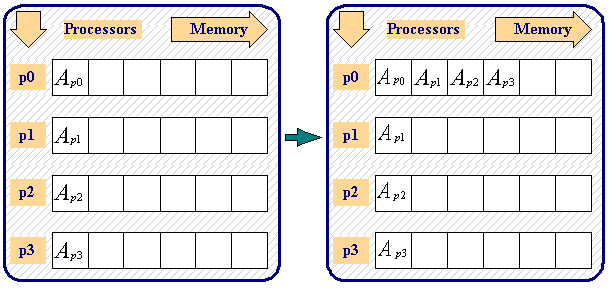 * wie Send in jedem Prozess und n * Recv im Root
* <code>#include <stdio.h>
#include <mpi.h>
void main(int argc, char argv[])
{
int rank,size;
double param[16],mine;
int sndcnt,rcvcnt;
int i;
MPIInit(&argc, &argv);
MPICommrank(MPICOMMWORLD,&rank);
MPICommsize(MPICOMMWORLD,&size);
sndcnt=1;
mine=23.0+rank;
if(rank==7) rcvcnt=1;
MPIGather(&mine,sndcnt,MPIDOUBLE,param,rcvcnt,MPIDOUBLE,7,MPICOMMWORLD);
if(rank==7)
for(i=0;i<size;++i) printf("PE:%d param[%d] is %f \n",rank,i,param[i]]);
MPIFinalize();
}</code>
*
* wie Send in jedem Prozess und n * Recv im Root
* <code>#include <stdio.h>
#include <mpi.h>
void main(int argc, char argv[])
{
int rank,size;
double param[16],mine;
int sndcnt,rcvcnt;
int i;
MPIInit(&argc, &argv);
MPICommrank(MPICOMMWORLD,&rank);
MPICommsize(MPICOMMWORLD,&size);
sndcnt=1;
mine=23.0+rank;
if(rank==7) rcvcnt=1;
MPIGather(&mine,sndcnt,MPIDOUBLE,param,rcvcnt,MPIDOUBLE,7,MPICOMMWORLD);
if(rank==7)
for(i=0;i<size;++i) printf("PE:%d param[%d] is %f \n",rank,i,param[i]]);
MPIFinalize();
}</code>
* MPIALLGATHERund anschließend direkt einmacht das gleiche wieMPIGATHERMPIBCAST,→ Daten werden direkt an alle Prozesse verteilt *int MPIScatter ( void* sendbuffer, int sendcount, MPIdatatype sendtype, void* recvbuffer, int recvcount, MPIDatatype recvtype, int rank, MPIComm comm )sendet Daten vom Rootprozess an alle Prozesse abhängig vom Rank *MPICOMMWORLD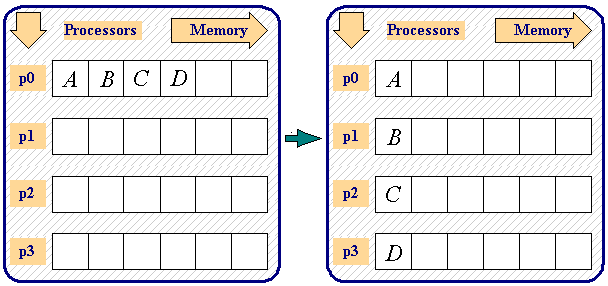 * wie n * Send im Root und Recv in jedem Prozess
* <code>#include <stdio.h>
#include <mpi.h>
void main(int argc, char *argv[]) {
int rank,size,i;
double param[8],mine;
int sndcnt,rcvcnt;
MPIInit(&argc, &argv);
MPICommrank(MPICOMMWORLD,&rank);
MPICommsize(MPICOMMWORLD,&size);
rcvcnt=1;
if(rank==3) {
for(i=0;i<8;++i) param[i]=23.0+i;
sndcnt=1;
}
MPIScatter(param,sndcnt,MPIDOUBLE,&mine,rcvcnt,MPIDOUBLE,3,MPICOMMWORLD);
for(i=0;i<size;++i) {
if(rank==i) printf("P:%d mine is %f n",rank,mine);
fflush(stdout);
MPIBarrier(MPICOMMWORLD);
}
MPIFinalize();
}</code>
* MPIALLREDUCE — used to combine the elements of each process's input buffer and stores the combined value on the receive buffer of all group members.
* User-Defined Reduction Operations — enable reduction to be defined as an arbitrary operation.
* Gather / Scatter Vector Operations — MPIGATHERV and MPISCATTERV allow a varying count of data from/to each process.
* Other Gather / Scatter Variations — MPIALLGATHER and MPIALLTOALL
* No root process specified: all processes get gathered or scattered data.
* Send and receive arguments are meaningful to all processes.
* MPISCAN — used to carry out a prefix reduction on data throughout the group and returns the reduction of the values of all of the processes.
* MPIREDUCESCATTER combines an MPIREDUCE and an MPISCATTERV.
==== Kommunikatoren ====
* Kommunikatoren fassen Prozesse zusammen und ermöglichen ihnen die Kommunikation miteinander
*
* wie n * Send im Root und Recv in jedem Prozess
* <code>#include <stdio.h>
#include <mpi.h>
void main(int argc, char *argv[]) {
int rank,size,i;
double param[8],mine;
int sndcnt,rcvcnt;
MPIInit(&argc, &argv);
MPICommrank(MPICOMMWORLD,&rank);
MPICommsize(MPICOMMWORLD,&size);
rcvcnt=1;
if(rank==3) {
for(i=0;i<8;++i) param[i]=23.0+i;
sndcnt=1;
}
MPIScatter(param,sndcnt,MPIDOUBLE,&mine,rcvcnt,MPIDOUBLE,3,MPICOMMWORLD);
for(i=0;i<size;++i) {
if(rank==i) printf("P:%d mine is %f n",rank,mine);
fflush(stdout);
MPIBarrier(MPICOMMWORLD);
}
MPIFinalize();
}</code>
* MPIALLREDUCE — used to combine the elements of each process's input buffer and stores the combined value on the receive buffer of all group members.
* User-Defined Reduction Operations — enable reduction to be defined as an arbitrary operation.
* Gather / Scatter Vector Operations — MPIGATHERV and MPISCATTERV allow a varying count of data from/to each process.
* Other Gather / Scatter Variations — MPIALLGATHER and MPIALLTOALL
* No root process specified: all processes get gathered or scattered data.
* Send and receive arguments are meaningful to all processes.
* MPISCAN — used to carry out a prefix reduction on data throughout the group and returns the reduction of the values of all of the processes.
* MPIREDUCESCATTER combines an MPIREDUCE and an MPISCATTERV.
==== Kommunikatoren ====
* Kommunikatoren fassen Prozesse zusammen und ermöglichen ihnen die Kommunikation miteinander
* enthält alle Prozesse * es gibt Intrakommunikatoren (Gruppe von Prozessen, die in dieser einen eindeutigen Rang haben) und Interkommunikatoren (Kommunikation zwischen Intrakommunikatoren) * Erzeugen von Intrakommunikatoren * MPI-1: Aufspalten (MPICommsplit), duplizieren (MPICommdup) vorhandener Intrakommunikatoren, erzeugen einer neuen Gruppe aus Prozessen, neu anordnen von Prozessen einer Gruppe * MPI-2: verbinden zweier Anwendungen und mergen ihrer Prozesse, neue Prozesse erzeugen *MPICommsplit(MPIComm comm, int color, int key, MPIComm *newcomm)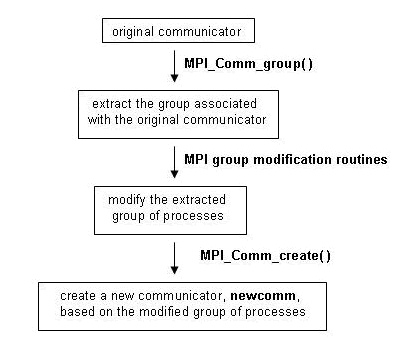 *
* spaltet einen Kommunikator in Subkommunikatoren * Reihenfolge nachkey, wenn identisch nach Rang incomm
*extrahiert das Handle einer Prozessgruppe aus einem Kommunikator *MPIGroupincl(MPIGroup group, int n, int *rank, MPIGroup *newgroup)erzeugt eine neue Gruppe aus den inrankangegebenen Prozessen * werden inrankProzesse angegeben, die nicht in der Gruppegroupsind, bricht MPI mit einem Fehler ab, ebenso bei doppelten Einträgen * wennn0 ist, ist die neue GruppeMPIEMPTYGROUP*MPIGroupexclhat die gleiche Syntax und erzeugt eine Gruppe mit den Prozessen außer den inrankangegebenen * die Reihenfolge der Ranks inrankist unerheblich für die neuen Ranks innewgroup* wennn0 ist, ist die neue Gruppe gleich der altenMPIGroupunion(MPIGroup group1, MPIGroup group2, MPIGroup *newgroup)
*MPIGroupintersectionundMPIGroupdifferenceerzeugt zwei Gruppen eine neue durch Anwendung der entsprechenden Mengenoperation * Abfragen der Informationen der Gruppen *MPIGroupsize(MPIGroup group, int *size)**MPIGrouprank(MPIGroup group, int *rank)MPIUNDEFINED*wenn aufrufender Prozess nicht zur Gruppe gehört *MPIgrouptranslateranks(MPIGroup group1, int n, int *rank1, MPIGroup group2, int *rank2)MPIGroupcompare(MPIGroup group1, MPIGroup group2, int *result)*result:MPIIDENToder,MPISIMILARMPIUNEQUALzerstört eine Gruppe **MPIGroupfree(MPIGroup *group)MPICommcreate(MPIComm comm, MPIGroup group, MPIComm *newcomm)zerstört einen Kommunikator ===== Links ===== * Parallelrechner und Parallelisierungskonzepte (Universität Karlsruhe) * Parallele Systeme (Universität Münster) * Parallele Programmierung (Uni Marburg) ===== ToDo ===== *erzeugt einen neuen Kommunikator auf Basis einer Gruppe * muss von allen betroffenen Prozessen aufgerufen werden * Prozesse, die nicht in der Gruppe sind, erhaltenMPICOMMNULLals Rückgabewert *MPICommfree(MPIComm *comm)Online-Learning anschauen* externe Quellen suchen *Gesetze Amdahl etc.* MPI-Standard * Architekturen verstehen (Shared Memory etc.)
*Metriken verstehen, Metriken (Formeln) für neue Topologie entwickeln*Leistungsbewertung (Gesetze Amdahl etc.)*OpenMP eher allgemein (Kombination mit MPI)*OpenMP-Webcast*Bibliotheken für Parallelrechner nur oberflächlich
* Lehrbrief korrigieren (falsche Parameter bei MPI-Funktionen) *Metriken für Baum erstellen




se/parallelrechner.txt · Zuletzt geändert: 2014-04-05 11:42 (Externe Bearbeitung)
Seiten-Werkzeuge
Falls nicht anders bezeichnet, ist der Inhalt dieses Wikis unter der folgenden Lizenz veröffentlicht: CC Attribution-Noncommercial-Share Alike 4.0 International
