Benutzer-Werkzeuge
se:datenbankentwicklung
**Dies ist eine alte Version des Dokuments!**
Datenbankentwicklung
Administration
- Benutzergruppe
ORADBAwird bei der Installation angelegt. * Benutzer dürfen alles (inkl.STARTUP/SHUTDOWN). * Operating System Authentication:SQLPLUS / AS SYSDBA*STARTUP*OPEN <> MOUNT(nur Verwaltungsaktionen möglich) *SHUTDOWN*TRANSACTIONAL, IMMEDIATE, ABORT* Client und Server kommunizieren über Oracle Net (Ports 1521 und 8080) * Listener steuern:lsnrctlSTART/STOP/STATUS * Listener-Konfiguration: listener.ora * Ändern der DB-Portnummer: listener.ora ändern,ALTER SYSTEM SET LOCALLISTENER="(ADDRESS=(PROTOCOL=TCP)(HOST= rzn055.hv.fh-nuernberg.de)(PORT=1522))"; ALTER SYSTEM REGISTER;- Ändern der Web-Portnummer: als
SYSTEM: EXEC DBMSXDB.SETHTTPPORT(8080);oder über Oberfläche unter Administration → Manage HTTP access* Remote-Zugriff auf Weboberfläche: alsSYSTEM: EXEC DBMSXDB.SETLISTENERLOCALACCESS(FALSE);
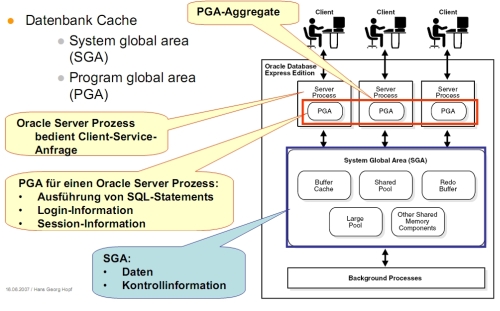
- System Global Area: Benutzerübergreifender Cache
- Data Buffer Cache: Abgefragte oder modifizierte Daten, vermeidet physikalischen Zugriff auf Dateien, zuletzt bearbeitete Blöcke
- Redo Log Buffer: Redo-Informationen werden zwischengespeichert bis sie physikalisch geschrieben werden
- Dictionary Cache: Data Dictionary Informationen
- Shared SQL Pool: Benutzerübergreifende Informationen (übersetzte SQL-Statements, Tabellenbeschreibungen, Stored Procedures)
- Large Pool: Optionaler Bereich zum Puffern von größeren I/O-Operationen
- Größe wird bei der Installation gesetzt: SGA Target, Größe der SGA-Komponenten wird automatisch angepasst
- Mögliche Fehler:
unable to allocate shared memory, no free buffers in buffer pool
* Prozesskommunikation über Speicherbereiche * speichert permanente Verwaltungsinformationen
* Program Global Area: Speicher für jede Session (Prozess) individuell
- Größe wird bei Installation gesetzt: PGA-Aggregat-Größe kann angepasst werden, individuelle PGA-Größen werden automatisch angepasst
- Mögliche Fehler:
out of process memory
- Datenbankspeicher
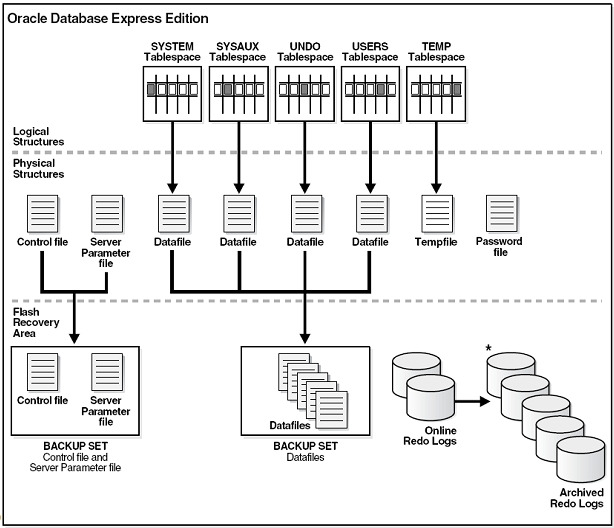
* Zusammenfassung von logischen und physischen Strukturen * Enthalten Nutzdaten und Metadaten sowie Kontrolldaten (z.B. zum Datenbankstart) * **Logische Strukturen** sind nur der DB bekannt * **Physikalische Strukturen** sind die Dateien auf der Festplatte * **Recovery-bezogene Strukturen** (z.B. Redo-Logs und Backups) dienen der Wiederherstellung des Systems (z.B. nach Betriebssystemausfällen), werden in der Flash Recovery Area abgelegt
* Tablespaces
- System- und Nutzdaten liegen im permanenten Tablespace
- SYS hat SYSTEM als permanenten Tablespace, alle übrigen Benutzer USERS
* SYSTEM * Data Dictionary, Tabellen mit administrativen Informationen über die DB (in Schema SYS) * SYSAUX * Hilfstablespace für einige Komponenten/Produkte (z.B. HR) * UNDO * Rollback, Read Consistency, Flashback Queries * USERS * Permanente Benutzerdaten * TEMP * temporäre (Zwischen-)Ergebnisse, Parallelisierung und Performanceverbesserung von Operationen (z.B. Sortierung), eine oder mehrere Dateien
* Physikalische Strukturen
- Dateien und temporäre Speicherung (datafiles, tempfiles)
- Datafiles: Betriebssystem-Dateien, nur von Oracle-Instanz bearbeitbar
- Tempfiles: nur für temporary Tablespace
- Kontroll-Dateien (control files)
- Enthält spezifische Informationen, die für das Funktionieren der Datenbank essentiell sind
- Server-Parameter Dateien (server parameter file)
- SPFILE enthält Initialisierungsparameter (binär)
- Parameterwerte werden mit ALTER SYSTEM verändert
- Passwort-Datei (password file)
- Authentifizierung für Remote-Zugriff des SYS-Users
- Enthält verschlüsseltes SYS-Passwort
* Flash Recovery Area
- Verzeichnis, getrennt von der Datenbank
- Enthalten:
- Backup der Datenbank-Dateien (Datenbank-Dateien, Control-Dateien, Server Parameter Files SPFILES)
- Gespeichert in Backup Sets
- Bestehend aus Backup pieces
- Online redo log Dateien
- Aufnahme aller Datenbankänderungen
- Archivierte redo log Dateien
- Dauerhafte Archivierung der Datenbankänderungen (ARCHIVELOG Mode)
- Speicherort
- Initialisierungsparameter DBRECOVERYFILEDEST * Einloggen als SYS-DBA: / SYSDBA *
ALTER SYSTEM SET DBRECOVERYFILEDEST = 'newpath';* Starten einer PL/SQL-Prozedur zum verschieben der Information:@?/sqlplus/admin/movelogs* Größe * Initialisierungsparameter DBRECOVERYFILEDESTSIZE * Einloggen als SYS-DBA: / SYSDBA *ALTER SYSTEM SET DBRECOVERYFILEDESTSIZE = newsize;(newsize= nK (kilobytes), nM (megabytes) or nG (gigabytes)) * Schemas * Logische Container für DB-Objekte * Sind einem User zugeordnet * Datenbankobjekt = Schemaobjekt * Privilegien: System-/Objekt-Privilegien
* Rollen: CONNECT (verbinden und abfragen), RESOURCE (Objekte erzeugen), DBA (alles außer STARTUP und SHUTDOWN) * Benutzer: interne (z.B. SYS, SYSTEM) und Datenbankbenutzer * Einloggen, auch wenn DB heruntergefahren ist: AS SYSDBA * Passwort ändern: ALTER USER user IDENTIFIED BY pass
* Datenaustausch * Export/Import: proprietäres Format *expdp, impdp(kein XML),exp, imp(kein FLOAT und DOUBLE)
* Unload/Load: CSV etc. * Weboberfläche (nur eine Tabelle auf einmal, keine Filterung, CSV oder XML),sqlldr(verschiedenste Formate möglich) * SQL*Loader * Methoden: conventional, direct, external tables *sqlldr hr/hr DATA=dependents.dat CONTROL=dependents.ctl LOG=dependents.log
* Dump *sqlplus SYSTEM/password
*CREATE OR REPLACE DIRECTORY dmpdir AS 'c:\oraclexe\app\tmp';*GRANT READ,WRITE ON DIRECTORY dmpdir TO hr;*ALTER USER hrdev IDENTIFIED BY hrdev;
*expdp SYSTEM/password SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp LOGFILE=expschema.log*impdp SYSTEM/password SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp REMAPSCHEMA=hr:hrdev EXCLUDE=constraint, refconstraint, index TABLEEXISTSACTION=replace LOGFILE=impschema.log
* Backup und Recovery * Schützen aller DB-Dateien (Daten, Control, SPFILE, REDO LOG) * Sicherung der gesamten Datenbank in der Flash Recovery Area
* Recovery Manager (RMAN) bedienbar über Kommandozeile/Script
* Backup Retention Policy: Zwei vollständige Backups müssen vorgehalten werden, ARCHIVELOG: zusätzlich alle Logs für media recovery * ARCHIVELOG schützt gegen Fehler des BS, der Oracle Instanz und der Media Disk * Online-(ARCHIVELOG)/Offline-(NOARCHIVELOG)Backup * Ein-/Ausschalten * SQLPLUS SYS/password AS SYSDBA * SHUTDOWN IMMEDIATE * STARTUP MOUNT * ALTER DATABASE [NO]ARCHIVELOG; * ALTER DATABASE OPEN;
* Flashback Queries (Anzeige historischer Daten) *SELECT * FROM employees AS OF TIMESTAMP TOTIMESTAMP('2005-04-04 09:30:00', 'YYYY-MM-DD HH:MI:SS') WHERE lastname = 'Chung';*INSERT INTO employees (SELECT * FROM employees AS OF TIMESTAMP TOTIMESTAMP('2005-04-04 09:30:00', 'YYYY-MM-DD HH:MI:SS') WHERE lastname = 'Chung');* Tabellen löschen bedeutet Verschieben in den Papierkorb (Recycle Bin), Leeren bei Speicherbedarf oder manuell
* Datenbankstruktur *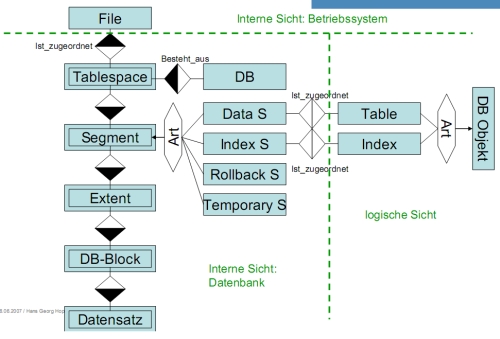
* 3 Ebenen: externe (VIEW), logische (TABLE), interne (INDEX)
* Eine DB ist ein Programmpaket zur Manipulation von gespeicherten Daten (Benutzer-/Verwaltungsdaten) * Physische Sicht (Dateien) != logische Sicht (Tablespaces) * Dateigruppen * Datenbankdateien (Tabellen, Data Dictionary, PL/SQL, Index, Nutzdaten) * REDO-Logs (Protokollierung aller Änderungen, jede DB hat mind. 2, ARCHIVELOG: vor Überschreiben Sicherung) * Kontrolldateien (Zeitpunkt der DB-Erstellung, Namen der DB-Dateien und der Logs) * Tablespaces * Datenbankdateien sind nur benannter Speicherplatz → logische Struktur darüber (Tablespaces) * eine Datei → ein Tablespace, ein Tablespace → mehrere Dateien * Standard-Tablespaces: SYSTEM, TEMP, USERS, Rollback Data, Tools *SELECT * FROM usertablespaces;===== PL/SQL (Schwerpunkt der Klausur) ===== * PL/SQL: Procedural Language extension to SQL * Bietet eine Blockstruktur für Code an * Bietet prozedurale Konstrukte an (Variablen, Kontrollstrukturen etc.) **CREATE TABLESPACE Users DATAFILE 'data3.ora' SIZE 100MB;*ALTER TABLESPACE system ADD DATAFILE 'data2.ora' SIZE 200MB;*DROP TABLESPACE TA [INCLUDING CONTENTS];* Modi: Online/Offline:ALTER TABLESPACE TA [ONLINE | OFFLINE] [NORMAL | TEMPORARY | IMMEDIATE];*TRUNC TABLE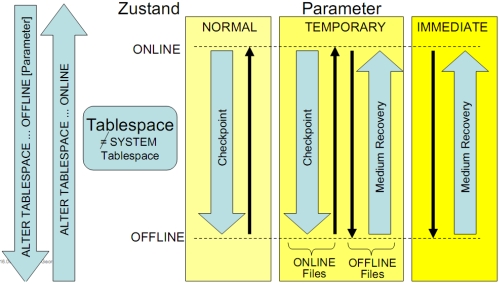
* Datenbankobjekte/Segmente: Tabellen, Indizes, Recovery-Informationen * Tablespaces sind in Segmente (Daten, Index, Rollback, temporär) unterteilt * Jedes DB-Objekt belegt genau ein Segment * Problem: Fragmentierung * Segmente bestehen aus Extents (unteschiedlicher Größe) * Anfangs-/Folge-Extent
* Die Festlegung der Anfangs-Extent-Größe erfolgt über den Parameter initial * Die Anzahl der bei der Erstellung eines Segments mit angelegten Folge-Extents wird mit dem Parameter minextents definiert. * Die Anzahl der insgesamt maximal möglichen Folge-Extents wird mit dem Parameter maxextents definiert. * Die Größe der Folge-Extents kann festgelegt bzw. dynamisch verändert werden. Die Festlegung der Folge-Extent-Größe erfolgt über den Parameter next * Der Parameter pctincrease gibt den Wachstumsfaktor der Extents in % an. *bewirkt Zurücksetzen des belegten Speichers (<>DELETE FROM TABLE) * Festlegung der Parameter bei Erstellung des Tablespaces oder der DB-Objekte *CREATE PFILE [='pfilename'] FROM SPFILE [='spfilename'];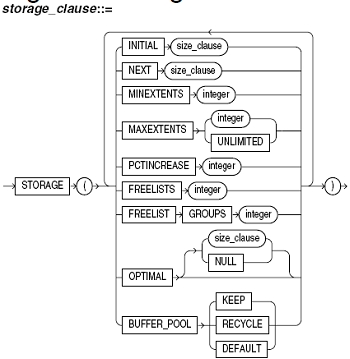
* Extents bestehen aus Oracle-Datenblöcken (2KB) * Block-Kopf * Verwaltungsinformationen 57 Byte * Datensatz-Directory, für jeden im Block abgelegten Datensatz 2 Byte * Transaktionsdirectory (23 Byte pro Eintrag) * initrans (1 (default) - 255) * maxtrans
* Block-Datenbereich * Freibereich (Speicher für sich vergrößernde Datensätze) * Einfüge-Bereich (neue Datensätze) * Der pctfree-Parameter gibt an, wie viel % des DB-Block-Datenbereiches als Freibereich genutzt werden sollen. * Der pctused-Parameter gibt den Mindestfüllgrad eines DB-Blockes an. * Insert-Operationen werden an Blöcken vorgenommen, deren Mindestfüllgrad noch nicht erreicht ist. Damit wird eine gleichmäßige Belegung der DB-Blöcke erreicht. * Der freelists-Parameter gibt die Anzahl der FREE-Listen an. * Block-Verwaltung *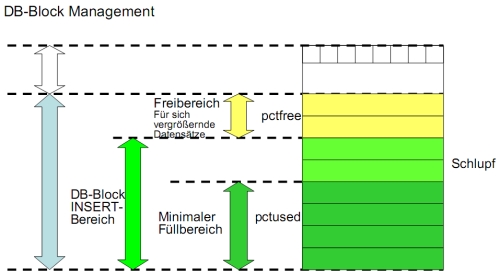
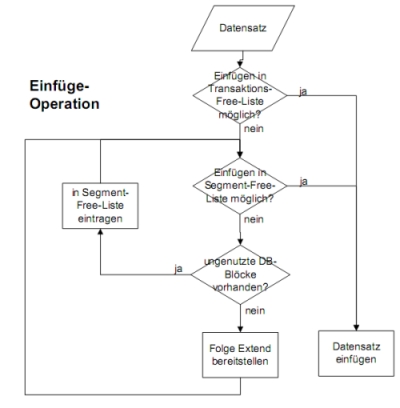
* Überlauf: zu lange Blöcke werden in einen neuen Block eingetragen und im ursprünglichen eine Referenz erzeugt * Freispeicherverwaltung: Blöcke mit Füllstand unter pctused werde in FREE BLOCK-Listen eingetragen * Transactions-FREE-Liste: Innerhalb einer Transaktion freiwerdende Blöcke * Segment-FREE-Liste: Blöcke, deren Füllstand unter pctused liegt und die nicht in einer Transaktion bearbeitet werden *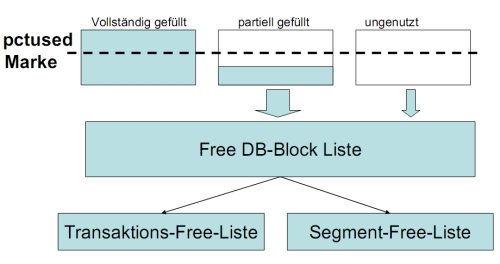 *
* 
* Datensätze * Kopf (Verwaltungsinformationen, 2-5 Byte) * ID (2 Byte) * Anzahl Spalten (1 Byte, obligatorische Spalte row-id → 255 Spalten für Benutzer) * Verkettungsadressen (1 Byte) * Cluster-Schlüsselinformationen (1 Byte) * Rumpf (Daten) * Spaltenlänge: 1 Byte (NUMBER, CHAR, DATE), 3 Byte (VARCHAR, VARCHAR2, LONG, RAW, LONG RAW) * Spaltendaten
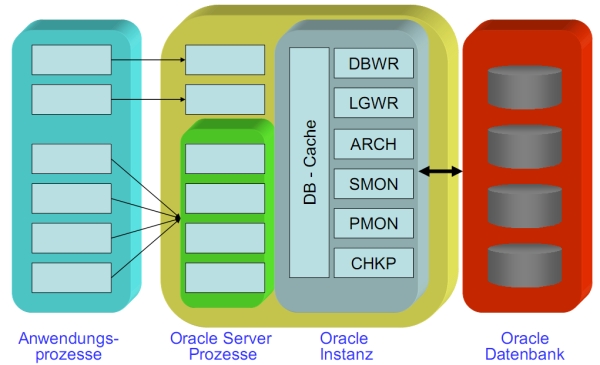
* Dictionary Views: DBAFREESPACE, USERTABLESPACES, USERSEGMENTS, USEREXTENTS, USERTABLES, USERTSQUOTAS * Architektur * Oracle Instanz * SGA, PGA, Hintergrundprozesse * Definiert durch SGA, Files und DB-Prozesse * Hat eindeutige SID * Orace Server-Prozesse * Parsen und Ausführen von SQL, Lesen von DB-Blöcken aus Files
* Konfiguration * Dedicated Server: Jeder Anwenderprozess hat einen Serverprozess * Multi-Threaded Server: Anwenderprozess übergibt Request an Dispatcher → Request-Queue in SGA → Abarbeitung durch beliebigen Serverprozess → Ergebnis wird in Response-Queue in SGA gelegt * Beide Möglichkeiten können gleichzeitig genutzt werden, Entscheidung über Parameter beim Start des Anwenderprozesses * viele Benutzer, wenig Last → MTS * viele Prozesse, hohe Last → DS * Client-/Server-Architektur * Schützt Server-Programme, unterschiedliche Rechner für Client und Server * Hintergrundprozesse * Recoverer (RECO): Recovery bei verteilten DBs * Process Monitor (PMON): Recovery für fehlerhafte Anwenderprozesse * System Monitor (SMON): Recovery beim Systemstart * Database Writer (DBWR): liest/schreibt Blöcke aus Cache in DB und umgekehrt * Redo Log Writer (LGWR): liest/schreibt REDO-Log * Checkpoint (CKPT): übernimmt die Checkpoint-Aktivitäten vom LGWR (optional)
* Archiver (ARCH): archiviert REDO-Logs * Lock (LCKn): Aufgaben bei Parallel-Server-Konfiguration (optional) * Systemparameter editieren **CREATE SPFILE [='pfilename'] FROM PFILE [='spfile_name'];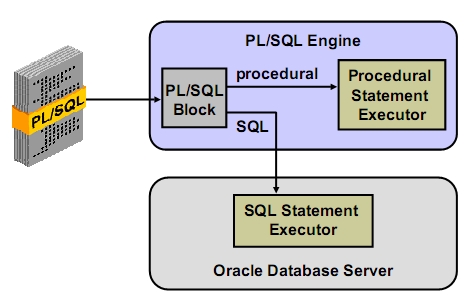 * Vorteile
* Integration in Oracle Tools
* Modularisierte Anwendungsentwicklung
* Portabilität des PL/SQL-Codes
* Exception Handling
* Vorteile
* Integration in Oracle Tools
* Modularisierte Anwendungsentwicklung
* Portabilität des PL/SQL-Codes
* Exception Handling
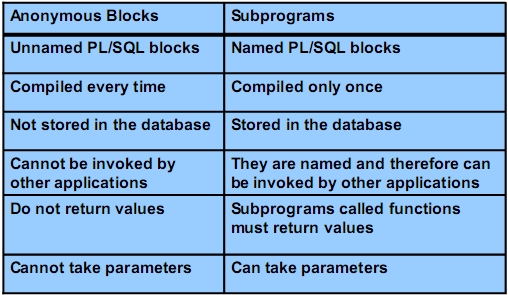
* PL/SQL-Blöcke * Aufbau * DECLARE: Variablen, Cursor, eigene Exceptions * BEGIN: SQL und PL/SQL * EXCEPTION: Fehlerbehandlung * END * Typen * Anonymous * Procedure * Function
* Speicherort: Server oder Anwendung * Variablen *[a-zA-Z][a-zA-Z0-9$_#]{0,29}
* Deklarierung/Initialisierung inDECLARE, Zuweisung inBEGIN*identifier [CONSTANT] datatype [NOT NULL] [:= | DEFAULT expr];* String-Begrenzung:q'!Das ist ein Text!'
* Typen * Scalar:CHAR, VARCHAR, LONG, INTEGER, BOOLEAN, DATEetc. * Composite: Zusammengesetzte Variablen aus mehrere Datentypen * Reference * LOB: Fotos, Filme etc. * Nicht-PL/SQL: Bind variables * Host-Variablen, die mitVARIABLEdeklariert werden und mit einem führenden:referenziert werden *SET AUTOPRINT ON* Substitution Variables * referenziert mit führendem&: Eingabe zur Laufzeit *ACCEPT varname PROMPT 'Text' * User Variable: deklariert mitDEFINE, referenziert mit&
*%TYPE-Attribut: Datentyp einer Spalte/Variable übernehmen (identifier table.columnname%TYPE;* Komplexe Datentypen * Records * ein oder mehrere Felder (Scalar, Record,) * Mögliche Boolean-Werte:TRUE, FALSE, NULL(!)DECODE
* Lexikalische Einheiten * Folgen von Zeichen, Zahlen, Whitespace und Symbolen * Typen: Identifier, Delimiter, Literals, Comments
* SQL-Funktionen * Nicht in PL/SQL verfügbar:,GROUP-FunktionenINTO
* SELECT in PL/SQL *wird benötigt * Abfragen müssen genaue eine Zeile zurückliefern * Variablenpriorität: Spaltennamen → lokale Variablen/Parameter → TabellennamenSQL%FOUND
* Cursor * Zeiger auf den privaten Speicherplatz des Oracle-Servers * Implizit: werden intern vom Oracle-Server erzeugt und verwendet (z.B. bei SQL-Statements) * Attributes:,SQL%NOTFOUND,SQL%ROWCOUNT
* Explizit: werden vom Programmierer definiert und verwendet
* Kontrollstrukturen *'CASE
*Expression <>CASEStatement * Behandlung von NULL bei booleschen Operationen * Schleifen *LOOP - EXIT WHEN - END LOOP*WHILE LOOP - END LOOP*FOR IN LOOP - END LOOP
* Nested Loops: LabelsINDEX BY) * werden üblicherweise eingesetzt, um Tabellenzeilen zu lesen * Deklaration mitTYPE* einfache Definition mit%ROWTYPE' * Collections *INDEX BYtables / assoziative Arrays * 2 Spalten: Key (int/string) / Value * dynamische Länge * Zugriff über Indextable(1)* verfügbare Methoden:EXISTS, COUNT, FIRST, LAST, PRIOR, NEXT, DELETE
* VARRAYs und Nested Tables * Cursors * manuelle Aktionen:OPEN, [LOOP], FETCH, [EXIT], CLOSE*CURSOR FORmacht alles automatisch * Attribute:%ISOPEN, %NOTFOUND, %FOUND, %ROWCOUNT
* entsprechen Pointern aus C (Referenz auf Speicherbereich) * Datentyp der Curosr-Variablen istREF CURSOR* Cursor sind statisch, Cursor-Variablen sind dynamisch * Exceptions * Exceptions sind Fehler, die während der Programmausführung auftreten * Können implizit oder explizit ausgelöst werden * Behandlung: Handler oder weiterwerfen * Es sind mehrere Handler pro Block erlaubt, aber lediglich einer wird abgearbeitet. * Vorhandene Exceptions: z.B.NODATAFOUND, TOOMANYROWS, ZERODIVIDE* Funktionen:
* nicht vordefinierte Exceptions behandeln:SQLCODE, SQLERRM* Eigene Exceptions werfen:RAISE* Eigene Fehlermeldungen analog zum Oracle-Server ausgeben:RAISEAPPLICATIONERROR(nur mit Nummer -20000 bis -20999)
* Prozeduren und Funktionen *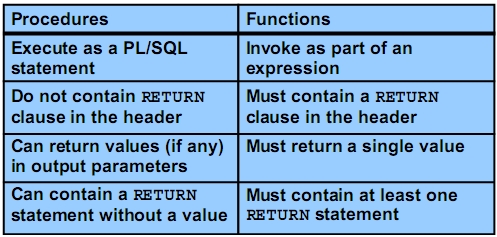 * Subprograms, benannte PL/SQL-Blöcke
*
* Subprograms, benannte PL/SQL-Blöcke
* 
* Parameter * Formal <> actual Parameters * Parameter Modes:IN, OUT, IN OUT*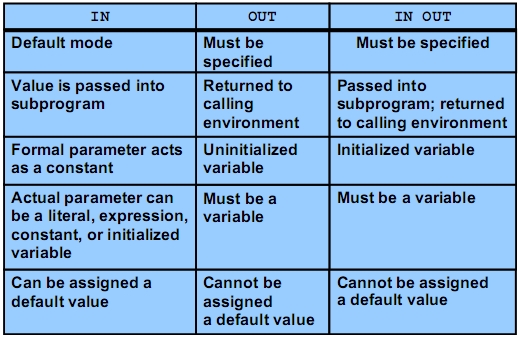
* Passing: positional, named, combination * Kein Zugriff auf Host-Variablem
* Gespeichert inUSERSOURCE, Namen stehen inoderALLSOURCEUSEROBJECTS) * Forward Declaration: Spezifikation eines Subprograms mit Semikolon abgeschlossen. Wird zu Beginn eines Blocks gemacht, damit Prozeduren auf die möglicherweise weiter unten im Quelltext implementierten Prozeduren zugreifen können.* Vorteile: einfach zu verwalten, Datensicherheit und -integrität, bessere Performance, bessere Codeverständlichkeit * Funktionen können in SQL-Statements verwendet werden:SELECT, WHERE, HAVING, ORDER BY, GROUP BY, VALUES, SET* Aber nur, wenn: in der DB gespeichert, nur IN Parameter, nur SQL-Datentypen verwenden, Parameter positional * Packages * Gruppierung von logisch zusammengehörenden Komponenten (Typen, Cursor, Subprograms etc.) * Bestehen aus Specification (quasi das Interface, Prozeduren sind public) und Body (die Implementierung) * Änderungen an der Specification erfordert Neukompilierung aller referenzierenden Subprogramme * Vorteile: Modularisierung, einfachere Verwaltung, einfacheres Anwendungsdesign, Information Hiding, bessere Performance (Package wird komplett und nur einmal in den Speicher geladen), Overloading * Overloading: Beispiele imSTANDARD-Package (z.B.TOCHAR
* Package Initialization Block:BEGIN-Teil am Ende des package body zur Initialisierung von Variablen. * Package State * Package wird beim ersten Aufruf initialisiert und bleibt die gesamte Session über bestehen. * Eindeutig für jede Session. * Hilfspakete:DBMSOUTPUT, UTLFILE, HTP, UTLMAIL, DBMSSCHEDULER* Dynamic SQL * Execution Flow: parse (compile time), bind (compile time), execute, fetch * Dynamic SQL ist ein String *EXECUTE IMMEDIATE .. INTO .. USING
* Triggers * PL/SQL-Block, der einer Tabelle, einem View, einem Schema oder einer Datenbank zugeordnet ist * Typen: Application/Database, Statement/Row Trigger * Timing:BEFORE, AFTER, INSTEAD OF* Trigger Events:INSERT, UPDATE [OF], DELETE* Row Trigger:FOR EACH ROW, :NEW, :OLD*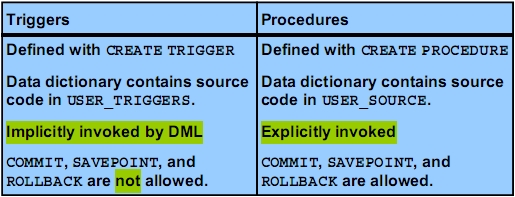
===== Web ===== * Voraussetzung: Database Access Descriptor (DAD) vorhanden * erzeugen mit DBA-Rechten *DBMSEPG.createdad (dadname ⇒ 'systemdad', path ⇒ '/systemdad/*');(beginnt bei Index 2) * Arbeitsweise: Requests kommen anonym auf dem Server an → Server liefert Seite aus * Kein Session-Konzept, kein Benutzerlogging * Designschritte *
* HTML-Ausgabe über HTP-/HTF-Package * Vorteile: Aufbau auf PL/SQL, integriert SQL und HTML, kein zusätzliches Konfigurationsmanagement * Webapplikationen werden als Packages erstellt * HTML-Erzeugung mit PL/SQL Web Toolkit → HTP/HTF
* GET vs. POST * gut für Debugging, Programmstruktur wird offenbart, Bookmarks möglich, begrenzte Länge der URL
* mehrere Parameter (Array): * Application Design
* High Level Storyboard: Screens und Navigation (Site Map)
* Detailed Storyboard
* Alle Elemente, auf die der Benutzer klicken kann
* Nicht alle Datenfelder, nur soviel um die ausgeführte Aktion erkennen zu können
* Jeder Ausgang aus einer Seite wird mit einem Pfeil mit dem resultierenden Screen verbunden
* Application Flow Diagram: Welche Daten werden zwischen den Seiten ausgetauscht (abwechselnd Procedure/Screen)
* Updates stellen aufgrund des fehlenden Sessionmanagements ein Problem dar (alte Daten müssen mit übergeben werden, um herauszufinden, ob jemand anderes die Daten in der Zwischenzeit bearbeitet hat)
* Skeletons für Procedures/Functions mit den ermittelten Parametern erzeugen
* Application Design
* High Level Storyboard: Screens und Navigation (Site Map)
* Detailed Storyboard
* Alle Elemente, auf die der Benutzer klicken kann
* Nicht alle Datenfelder, nur soviel um die ausgeführte Aktion erkennen zu können
* Jeder Ausgang aus einer Seite wird mit einem Pfeil mit dem resultierenden Screen verbunden
* Application Flow Diagram: Welche Daten werden zwischen den Seiten ausgetauscht (abwechselnd Procedure/Screen)
* Updates stellen aufgrund des fehlenden Sessionmanagements ein Problem dar (alte Daten müssen mit übergeben werden, um herauszufinden, ob jemand anderes die Daten in der Zwischenzeit bearbeitet hat)
* Skeletons für Procedures/Functions mit den ermittelten Parametern erzeugen
* Page Design * Beispielseiten erstellen, Fokus auf Layout → Designer machen lassen * Übliche Tipps: kein Splashscreen, Browsertests, wenige Grafiken, Web Standards, Formularelemente zur Einschränkung der Benutzereingaben, kontrastreicher Text
* Conversion * WebAlchemy, html2plsql → statische Seiten * Business Logic * die statischen Seiten mit "echter" Logik versehen
* Modularization
* Trennung von HTML-Ausgabe und Logik * Header-/Footer-Procedures etc. * eigene projektübergreifende Webkomponenten erzeugen
===== Modellierung ===== ===== ToDo ===== * Unterschiede Host- (auch Bind-/Global-), User-, Substitution-Variablen














se/datenbankentwicklung.1221409450.txt.gz · Zuletzt geändert: 2014-04-05 11:42 (Externe Bearbeitung)
Seiten-Werkzeuge
Falls nicht anders bezeichnet, ist der Inhalt dieses Wikis unter der folgenden Lizenz veröffentlicht: CC Attribution-Noncommercial-Share Alike 4.0 International
