Benutzer-Werkzeuge
se:informationstheorie
**Dies ist eine alte Version des Dokuments!**
Inhaltsverzeichnis
Informationstheorie und Codierung
Überblick
- Quellencodierung beseitigt Redundanz in der Nachricht
- Kanalcodierung fügt der Nachricht wieder Redundanz hinzu (z.B. zur Fehlerkorrektur)
Informationstheorie
- basiert auf grundlegenden Arbeiten von Shannon
- eine Quelle liefert informationskennzeichnende Zeichen xi aus einem q Zeichen umfassenden Alphabet X mit gewissen Wahrscheinlichkeiten
- bei stationäre Quellen sind die Wahrscheinlichkeiten, mit denen die Quelle Zeichen abgibt nicht von der Zeit abhängig
- bei gedächtnislosen Quellen sind die Wahrscheinlichkeiten der Zeichen unabhängig von zuvor oder im Anschluss gesendeten Zeichen
- aus den Elementen des Zeichenvorrats können Worte wi der Länge mi gebildet werden. Es lassen sich qm verschiedene Worte gleicher Länge m herstellen
- eine Codierung ist die Vorschrift zur eindeutigen Abbildung der Zeichen eines Zeichenvorrats A auf Codeworte, die aus den Zeichen eines Zeichenvorrats B gebildet werden: C(xi) = wi
- Beispiele für Codes: Morse-Code, ASCII-Code, Dezimal-, Oktalzahlen etc.
- Information ist Abbau von Ungewissheit (Beispiel Zufallsexperiment: Ausgang vorher unbekannt, danach bekannt)
- Informationsgehalt I(xi)/bit = -ld p(xi)
- I(xi, xj) = I(xi) + I(xj)
- der Informationsgehalt ist umso größer, je unwahrscheinlicher das Zeichen ist
- jedes Zeichen eines binären Zeichenvorrats hat bei gleichwahrscheinlichem Auftreten einen Informationsgehalt von -ld (0,5) = 1
- die Entropie H ist der mittlere Informationsgehalt der Zeichen einer Quelle → Maß für statistische Unordnung bzw. Unsicherheit
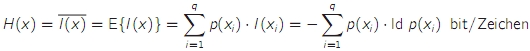
- die Entropie ist der Erwartungswert des Informationsgehalts
- die Entropie wird maximal, wenn alle Zeichen eines Zeichenvorrats gleich wahrscheinlich sind, Bezeichnung: Hmax oder H0
- die maximale Entropie wird auch als Entscheidungsgehalt einer Quelle bezeichnet
- der Unterschied zwischen H(x) und H0 wird als Redundanz bezeichnet: p = H0 - H(x)
- eine Redundanz kann auch für Codes angegeben werden: pcode = L - H(x) mit L = mittlere Codewortlänge
- relative Coderedundanz oder Weitschweifigkeit: (L - H(x)) / L, Codeeffizienz: H(x) / L
- ein optimaler Code besitzt unter bestimmten Randbedingungen (insb. ganzzahlige Wortlängen) die geringstmögliche Redundanz bzw. größtmögliche Effizienz
- eine Quelle, deren Gedächtnis K Zeichen in die Vergangenheit reicht, wird als Markov-Quelle K-ter Ordnung bezeichnet
- allg. Markov-Quelle = Markov-Quelle 1. Ordnung, gedächtnislose Quelle = Markov-Quelle 0. Ordnung
- die bedingte Entropie H(x|s) ist der Mittelwert (über alle Zustände) des mittleren Informationsgehalts eines Zeichens, das in einem bestimmten Zustand der Quelle abgegeben wird
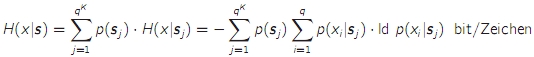
- die bedingte Entropie kann nie größer werden als die "normale" Entropie
- die Verbundentropie (H(x,s) ist der mittlere Informationsgehalt von ganzen Ausgangsfolgen einer Markov-Quelle
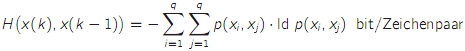
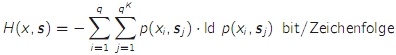
- H(x,s) = H(x|s) + H(s) wobei H(s) wiederum eine Verbundentropie ist
- beim Erhöhen der Nachrichtenlänge nähert sich der mittlere Informationsgehalt pro Zeichen asymptotisch der bedingten Entropie




Übertragungskanäle
- abstraktes Kanalmodell des diskreten Kanals: x → Modulator → physikalischer Kanal → Demodulator → y
- die Aufgabe von Modulator und Demodulator ist es, einen möglichst guten diskreten Kanal zu bilden
- die Aufgabe von Codierer und Decodierer ist es, eine zuverlässige Übertragung über diesen Kanal zu gewährleisten
- Demodulationsverfahren
- Hard-Decision: Ein- und Ausgabealphabet sind identisch
- Soft-Decision: liefert kontinuierlich verteilte Ausgangswerte
- bei Kanälen mit Gedächtnis hängt die Wahrscheinlichkeit des Ausgangszeichens nicht nur vom Eingangszeichen ab, sondern auch von den K vorangehenden Zeichen
- diskreter gedächtnisloser Kanal = Discrete Memoryless Channel (DMC)
- die Kanalmatrix enthält die Wahrscheinlichkeiten für die Ausgangszeichen
- p(yj|xi) = Wahrscheinlichkeit, dass yj empfangen wird, wenn xi gesendet wurde
- die Zeilensummen müssen 1 ergeben: 1 = p(y1|xi) + p(y2|xi) + … + p(yj|xi)
- p(xj|yi) heißt A-posteriori-Wahrscheinlichkeit, p(xj) heißt A-priori-Wahrscheinlichkeit
- der Detektor schließt aus dem empfangenen Zeichen yi auf das gesendete Zeichen xj
- Maximierung der A-posteriori-Wahrscheinlichkeit (Maximum-A-Posteriori-Probability-Detektion: MAP-Detektion) p(yi|xj) * p(xj)
- wenn die Quellenstatistik nicht bekannt ist, fällt p(xj) weg bzw. ist für alle Eingangszeichen gleich. Dann wird lediglich das Maximum von p(yi|xj) gesucht → Maximum-Likelihood-Detektor
- Entropien im Kanal
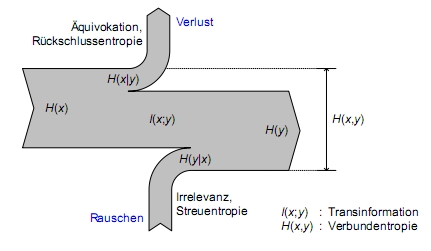
- die Verbundentropie des Kanals gibt den mittleren Informationsgehalt eines Ein-/Ausgangszeichenpaares an
- die bedingte Entropie H(x|y) heißt Rückschlussentropie oder Äquivokation und gibt den zusätzlichen Informationsgehalt eines Eingangszeichens an, wenn man das Ausgangszeichen kennt
- die bedingte Entropie H(y|x) heißt Streuentropie oder Irrelevanz und gibt den zusätzlichen Informationsgehalt eines Ausgangszeichens an, wenn man das Eingangszeichen bereits kennt
- H(x,y) = H(x|y) + H(y) = H(y|x) + H(x)
- die Transinformation I(x;y) ist ein Maß für die mittlere in einem Ausgangszeichen enthaltene relevante Information (mittlerer Informationsgehalt abzüglich Irrelevanz)
- I(x;y) = H(y) - H(y|x)
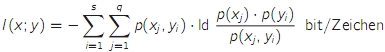
- Sonderfälle der DMC
- rauschfreier Kanal: Kanalmatrix hat in jeder Zeile nur einen Wert != 0
- verlustfreier Kanal: Kanalmatrix hat in jeder Spalte nur einen Wert != 0
- total gestörter Kanal: Ein- und Ausgangszeichen sind statistisch unabhängig voneinander
- symmetrischer Kanal: für die Elemente der Kanalmatrix gilt p(yi|xj) = 1 - p (Fehlerwahrscheinlichkeit des Kanals) wenn i = j, sonst = p / (q - 1)
- Sonderfall: Binary Symmetric Channel (BSC) und Binary Symmetric Erasure Channel (BSEC)
- die Kanalkapazität ist das Maximum der Transinformation für einen gegebenen Kanal
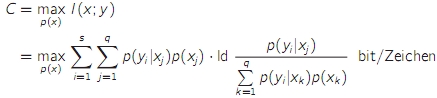
- bei symmetrischen Kanälen führen gleiche Wahrscheinlichkeiten der Eingangszeichen zur maximalen Transinformation und damit zur Kanalkapazität


se/informationstheorie.1235404333.txt.gz · Zuletzt geändert: 2014-04-05 11:42 (Externe Bearbeitung)
Seiten-Werkzeuge
Falls nicht anders bezeichnet, ist der Inhalt dieses Wikis unter der folgenden Lizenz veröffentlicht: CC Attribution-Noncommercial-Share Alike 4.0 International
